How Rittman Analytics Automates Project RAG Status Reporting using Vertex AI, DocumentAI, BigQuery & Looker
A common way to report on the progress of a project is through RAG (Red, Amber Green) status indicators for the project, at the overall level and by cost, schedule, scope, technology and data quality.
We’re currently piloting a Looker dashboard of this type to provide RAG status updates to our clients along with key project metrics and progress towards objectives, as shown in the screenshot below.
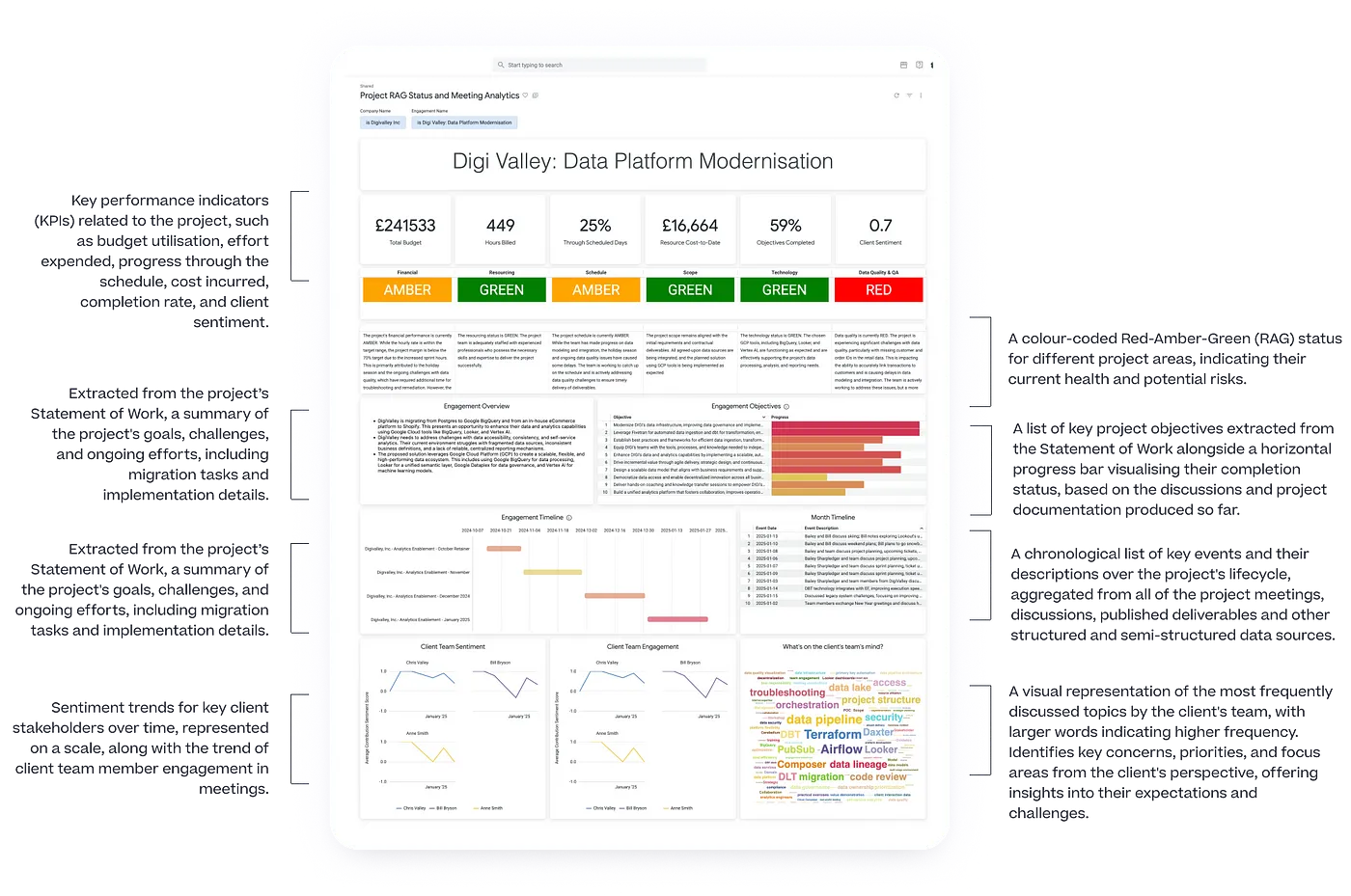
What’s interesting and is the subject of this blog is how we’re using generative AI, in the form of Google’s Vertex AI’s Gemini LLM, to assess each project engagement using a wide-ranging set of structured, semi-structured and unstructured data sources such as meeting transcripts, statements of work and project documentation.
Why RAG Status Reporting Is Hard to Automate
Creating a Looker dashboard that reports-on the number of tickets closed, amount of budget spent and other project metrics is relatively-straightforward but the numbers only tell part of the story.
What’s discussed in project meetings, in Slack messages and written in project documentation is the additional colour and context that’s used by a project manager when assigning RAG statuses to a project.
And of course all of those RAG statuses are set by reference to the project objectives, expected benefits and agreed deliverables contained within the project Statement of Work, typically a PDF document that’s easy for a project manager to read but usually impenetrable to a dashboarding tool.
To create our RAG status dashboard our approach was to source and centralize data from the following data sources and then use that data to prompt Vertex AI to classify the project engagement as either Red, Amber or Green RAG status:
Project metrics and KPI data from Harvest, Jira and Hubspot
Meeting transcripts from Fathom.video
Messages from Slack
Project documentation from Confluence Cloud
Statements of Work stored as PDFs and staged in Google Cloud Storage

In this blog we’ll focus on the unstructured and semi-structured data sources that were new to our internal BigQuery warehouse and are good examples of how you can use BQML functions to parse and analyze these types of non-conventional warehouse sources.
Let’s start with how we wrangled and added structure to our Fathom.video meeting transcripts, a source of project activity data that’s been key to this whole generative AI use-case.
Parsing & Structuring Fathom Meeting Transcripts
Like many organizations we’re big users of services such as Fathom.video that automatically transcribe meetings for you, and we’ve tried other service such as Fireflies.ai and Otter.ai in the past; crucially though for us, Fathom’s integrates with the Zapier service and enables us to set-up processing pipelines that can call other services, such as Google Vertex AI, and then store the final output in our Google BigQuery data warehouse.
When a new meeting transcript is published, we run that transcript raw text through a number of processing steps in a Zapier pipeline, analyzing the transcript’s overall sentiment, summarising it and then classifying the meeting as either an internal meeting or one of two client meeting types.

Each step in the pipeline sends a prompt to Vertex AI’s Gemini Flash-1.5 LLM to ask it to analyze the sentiment of the whole transcript, summarise it and classify it as either a client or internal meeting, with the raw transcript and all of the LLM-generated additions then written to a table in our Google BigQuery warehouse.
Taking just the raw transcript for now, we then process it using a set of dbt transformations as shown in the dbt Cloud lineage view below:

Each raw transformation is structured in pairs of two lines, the first line containing the time, speaker name and company name in brackets and the following line containing the words that person said, as shown in the example below:

We then parse this semi-structured data using the dbt staging-layer model below, using BigQuery SQL to split the raw text field content by newlines, group those lines together in pairs and then join them together to return one row per transcript speaker line.
SplitTranscript AS (
-- Split the entire transcript into individual lines
SELECT
recording_url, -- Optional identifier for the transcript
meeting_scheduled_start_time as meeting_start_ts,
ARRAY_AGG(line) OVER (PARTITION BY recording_url ORDER BY line_number) AS transcript_lines
FROM (
SELECT
recording_url,
meeting_scheduled_start_time,
line_number,
line
FROM (
SELECT
recording_url,
meeting_scheduled_start_time,
line_number,
line
FROM (
SELECT
recording_url,
meeting_scheduled_start_time,
SPLIT(transcript_plaintext, '\n') AS lines -- Split the transcript by newlines
FROM source
),
UNNEST(lines) AS line WITH OFFSET AS line_number -- Create a line index
)
)
),
GroupedTranscript AS (
SELECT
recording_url,
meeting_start_ts,
ARRAY(
SELECT
STRUCT(
transcript_lines[SAFE_OFFSET(i)] AS metadata_line,
transcript_lines[SAFE_OFFSET(i + 1)] AS text_line
)
FROM UNNEST(transcript_lines) AS line WITH OFFSET i
WHERE MOD(i, 2) = 0 -- Pair lines: metadata (even indices) with text (odd indices)
) AS paired_lines
FROM SplitTranscript
),
ParsedTranscript AS (
SELECT
recording_url,
REGEXP_EXTRACT(metadata_line, r'(\d+:\d+:\d+)') AS time_string,
TIMESTAMP_ADD(
meeting_start_ts,
INTERVAL TIME_DIFF(cast(REGEXP_EXTRACT(metadata_line, r'(\d+:\d+:\d+)') as time), TIME '00:00:00', SECOND) SECOND
) AS time,
trim(REGEXP_EXTRACT(metadata_line, r' - ([^(]+)')) AS contact_name,
trim(REGEXP_EXTRACT(metadata_line, r'\(([^)]+)\)')) AS company_name,
text_line AS text
FROM GroupedTranscript, UNNEST(paired_lines)
)
SELECT
time,
recording_url,
concat('fathom-',contact_name) as contact_id,
trim(contact_name) as contact_name,
concat('fathom-',company_name) as company_id,
trim(company_name) as company_name,
text
FROM
ParsedTranscript
WHERE
time IS NOT NULL
AND
text IS NOT NULL
GROUP BY
1,2,3,4,5,6,7This parsing not-only splits the meeting transcript into one row per-line of each meeting attendees’ words but it also parses-out the speaker names and their company names into their own table columns, which we use later-on in the pipeline to join these meeting conversations back to our central warehouse “contacts” dimension.

And now that we have the transcript in this more structured form, we can further process and aggregate the meeting contributions from each person through a series of dbt transformations as shown in the diagram below.

This BigQuery-powered dbt pipeline creates for us:
Per meeting attendee, a summary of what points they made in the meeting (their “contribution”) alongside a summary of the meeting as a whole, to help us understand the viewpoint, sentiment and engagement in that meeting for each attendee
Using all of a meeting attendees’ contributions that we aggregate into a single JSON string we then use BigQuery’s ML.GENERATE_TEXT function to pass these contributions to an LLM and ask it to return a JSON-formatted list of “jobs-to-be-done” for that person.
meeting_contributions AS (
SELECT
max(contact_fk) as contact_fk,
max(company_fk) as company_fk,
trim(contact_name) as contact_name,
CONCAT(
'[',
STRING_AGG(
TO_JSON_STRING(
STRUCT(
meeting_start_ts,meeting_title,meeting_contribution,
contribution_sentiment_category,meeting_engagement_level
)
)
ORDER BY
meeting_start_ts DESC
),
']'
) AS all_contributions
FROM
meeting_contributions_deduped
GROUP BY
3
),
jtdbs AS (
SELECT
contact_fk,
company_fk,
trim(contact_name) as contact_name,
REPLACE(REPLACE(REPLACE(ml_generate_text_llm_result, '```json', ''),'```',''),'\n','') AS jtbd_output
FROM
ML.GENERATE_TEXT(
MODEL `analytics_ai.gemini_1_5_flash`,
(
SELECT
contact_fk,
company_fk,
trim(contact_name) as contact_name,
CONCAT(
'You are a business consultant specialising in extracting actionable insights. Your role is to analyse the meeting contributions of ',
contact_name,
' and extract the main Jobs to Be Done (JTBDs) for their involvement in a specific project. Your task involves: 1. Identifying the primary JTBDs from the given contributions. 2. Listing the JTBDs clearly and concisely. 3. Providing a high-level summary of the identified JTBDs. 4. Extracting the most meaningful keywords from the JTBD descriptions. Ensure that these keywords are concise, reflective of the main themes, and avoid generic or overly common words. Output the results in a JSON format suitable for parsing and use in Google BigQuery, using the following structure: { "contact_name": "Contact Name", "identified_jtbds": [ { "jtbd_id": 1, "description": "Description of the first JTBD" } ], "summary": "High-level summary of the identified JTBDs.", "keywords": ["keyword1", "keyword2", "keyword3"] } Follow this schema strictly to ensure compatibility with downstream processing systems. The contributions from this person were: ',
meeting_contributions.all_contributions
) AS prompt
FROM
meeting_contributions
),
STRUCT(
0.2 AS temperature,
4096 AS max_output_tokens,
TRUE AS flatten_json_output
)
)
),
parsed_jtbd AS (
SELECT
contact_fk,
company_fk,
trim(contact_name) as contact_name,
JSON_VALUE(jtbd_output, '$.summary') AS jtbd_summary,
ARRAY(
SELECT AS STRUCT
CAST(JSON_VALUE(jtb, '$.jtbd_id') AS INT64) AS jtbd_id,
JSON_VALUE(jtb, '$.description') AS description
FROM UNNEST(JSON_EXTRACT_ARRAY(jtbd_output, '$.identified_jtbds')) AS jtb
) AS identified_jtbds,
ARRAY(
SELECT keyword
FROM UNNEST(SPLIT(REPLACE(REPLACE(REPLACE(JSON_QUERY(jtbd_output, '$.keywords'), '[', ''), ']', ''),'"',''), ',')) AS keyword
WHERE keyword IS NOT NULL
) AS keywords
FROM
jtdbs
)
SELECT
*
FROM
parsed_jtbdThe JSON-formatted results of this prompt response are then transform into two BigQuery nested sets of columns, one containing their jobs-to-be-done and the other a list of keywords from those jobs as shown in the example output below.

You can read about other use-cases we’ve developed for BigQuery’s ML.GENERATE_TEXT function in our blogs on Automating your Contacts List Segmentation using Google BigQuery, Vertex AI and the ML.GENERATE_TEXT function and Automating Insights and Dashboard Report-Level Narratives using Vertex AI Gemini 1.5-Flash, Looker Studio and Google BigQuery BQML.
Confluence Storage Format Parsing using Gen AI
Another key source of data for assessing the progress of a project is the documentation we create as meeting notes and the final engagement deliverables.
Fivetran have a Confluence Cloud connector that extracts into BigQuery all of the page and comments data we’re looking for, but the raw form of the content it brings across is in a weird XHTML Confluence Storage Format that isn’t easily parsed by BigQuery’s JSON query functional; also all of the content is versioned and so needs filtering to return the most recent version
SELECT
concat(concat('{{var('stg_confluence_docs_id-prefix')}}',s.name),'-',p.id,'-',p.version_number) as page_key,
concat('{{var('stg_confluence_docs_id-prefix')}}',s.name) as company_id,
s.name as space_name,
p.id AS page_id,
p.title as page_title,
p.version_number as page_version_number,
JSON_VALUE(v.page_body, '$.atlas_doc_format.value') as page_body ,
v.created_at as page_created_at_ts,
MAX(v.created_at) OVER (PARTITION BY p.id ORDER BY v.created_at RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) = v.created_at AS is_latest_version
FROM
...To parse this XHTML content we also used BigQuery’s ML.GENERATE_TEXT function, this time asking the Vertex AI LLM to first parse the XHTML-formatted data from Confluence and then summarise it, with those summaries then used later-on as parts of the input into the RAG status generation dbt model.
SELECT
* except(prompt,ml_generate_text_llm_result,ml_generate_text_rai_result,ml_generate_text_status),
JSON_VALUE(REPLACE(REPLACE(REPLACE(ml_generate_text_llm_result, '```json', ''),'```',''),'\n',''),'$.page_contents') page_contents,
JSON_VALUE(REPLACE(REPLACE(REPLACE(ml_generate_text_llm_result, '```json', ''),'```',''),'\n',''),'$.page_summary') page_summary
FROM
ML.GENERATE_TEXT( MODEL `{{var('stg_confluence_docs_fivetran_llm_name')}}`,
(
SELECT
page_key,
company_id,
space_name,
page_id,
page_title,
page_version_number,
page_created_at_ts,
CONCAT('For the page entited "', coalesce(page_title,''), '" in the confluence space named "',coalesce('space_name',''), '" Please extract the exact content of the page (with html tags stripped) and a summary of those contents and return it in JSON in this format : {\"page_contents\": \"<full_html-stripped_exact_contents_of_the_page_written_text_including_headers_and_subheaders>\", \"page_summary\": \"<summarisation_of_the_page_content_decisions_and_conclusions>\"} : ',j.page_body) AS prompt
FROM
confluence_json j),
STRUCT( {{var('stg_confluence_docs_fivetran_llm_temperature')}} AS temperature,
{{var('stg_confluence_docs_fivetran_llm_max_output_tokens')}} AS max_output_tokens,
TRUE AS flatten_json_output))If you’re wondering, the various REPLACE() functions around the output are to get rid of the extraneous ```json and linebreaks added by the LLM that would otherwise stop BigQuery’s JSON_VALUE function from working.
Statement of Work PDF Parsing using DocumentAI
To usefully assess the current status and progress of a project for a client, we really need to know what the original requirements, business objectives and agreed deliverables were for that project, information that can be found in a project-specific document called a “Statement of Work”, a free-form loosely-structured document stored as a PDF document.
Our strategy to access this statement of work data is to load it as embeddings into a vector storage table and then have ML.GENERATE_TEXT access it as a RAG (Retrieval Augmented Generation, another type of “RAG”) semantic search source, using two more BQML functions, ML.PROCESS_DOCUMENT and ML.GENERATE_EMBEDDING.

The steps to implement this pipeline are implemented by two Python notebooks, one that is run once-only and sets the pipeline up (code example here) and a second that loops through all of the PDFs in Google Cloud Storage and, for all that have not yet been ingested, runs through the following steps (code example here)
Define a BigQuery Object Table over each SoW PDF file using the CREATE EXTERNAL TABLE DDL command
CREATE OR REPLACE EXTERNAL TABLE `{DATASET_ID}.{table_name}`
WITH CONNECTION `{CONNECTION_NAME}`
OPTIONS ( uris = ['gs://{BUCKET_NAME}/{blob.name}'],
object_metadata = 'DIRECTORY' );2. Parse, chunk and create embeddings for the PDF data using the BQML ML.PROCESS_DOCUMENT function and the DocumentAI Layout Parser processor (note that if, like us, you’re based in the UK and use the europe-west2 Google Cloud Platform region this feature is only available in the EU and US multi-regions, and so you’ll have to parse the documents in the EU region and then copy the final output table over to europe-west2 at the end to bring this data into europe-west2)
CREATE OR REPLACE TABLE {DATASET_ID}.{result_table_name} AS (
SELECT * FROM ML.PROCESS_DOCUMENT(
MODEL {DATASET_ID}.layout_parser,
TABLE {DATASET_ID}.{table_name},
PROCESS_OPTIONS => (JSON '{{"layout_config": {{"chunking_config": {{"chunk_size": 250}}}}}}')
)
);
CREATE OR REPLACE TABLE {DATASET_ID}.{result_parsed_table_name} AS (
SELECT
uri,
JSON_EXTRACT_SCALAR(json , '
.content') AS content,
JSON_EXTRACT_SCALAR(json , '
.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM {DATASET_ID}.{result_table_name}, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json
);3. Generate vector embeddings for each of those parsed results tables using the ML.GENERATE_EMBEDDINGS function
CREATE OR REPLACE TABLE {DATASET_ID}.{embeddings_table_name} AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL {DATASET_ID}.embedding_model,
TABLE {DATASET_ID}.{result_parsed_table_name}
);4. And Finally, use the ML.GENERATE_TEXT function to create a prompt that uses the vector table as your RAG search source and outputs, in a structured form, the details in the engagement Statement of Work.
select * from (with objectives as (
SELECT
{deal_id} AS deal_id,
ml_generate_text_llm_result AS objectives_json,
NULL AS engagement_summary,
NULL AS engagement_deliverables
FROM
ML.GENERATE_TEXT(
MODEL `{DATASET_ID}.gemini_flash`,
(
SELECT
CONCAT(
'What are the (up to 10) objectives, expected business benefits and measurement metrics for this project? Be concise, add no preamble and respond in JSON format using output fields "objective_number", "objective_details", "expected_benefit","objective_metric" using the following context:',
STRING_AGG(FORMAT("context: %s and reference: %s", base.content, base.uri), ',')) AS prompt
FROM VECTOR_SEARCH(
TABLE `{DATASET_ID}.{deal_id}_embeddings`,
'ml_generate_embedding_result',
(
SELECT
ml_generate_embedding_result,
content AS query
FROM
ML.GENERATE_EMBEDDING(
MODEL `{DATASET_ID}.embedding_model`,
(
SELECT
'What are the objectives of this project? Be concise and use the following context' AS content
)
)
),
TOP_K => 10,
OPTIONS => '{{"fraction_lists_to_search": 0.01}}'
)
),
STRUCT(2048 AS max_output_tokens, TRUE AS flatten_json_output)
)),
engagement_summary as (
-- Engagement summary for deal_id {deal_id}
SELECT
{deal_id} AS deal_id,
NULL AS objectives_json,
ml_generate_text_llm_result AS engagement_summary,
NULL AS engagement_deliverables
FROM
ML.GENERATE_TEXT(
MODEL `{DATASET_ID}.gemini_flash`,
(
SELECT
CONCAT(
'Summarise the background, business requirements, solution and assumptions for this project. Be concise and respond in JSON format using output fields "Background", "Requirements","Solution", "Assumptions", add no preamble and be factual:',
STRING_AGG(FORMAT("context: %s and reference: %s", base.content, base.uri), ',')) AS prompt,
FROM VECTOR_SEARCH(
TABLE `{DATASET_ID}.{deal_id}_embeddings`,
'ml_generate_embedding_result',
(
SELECT
ml_generate_embedding_result,
content AS query
FROM
ML.GENERATE_EMBEDDING(
MODEL `{DATASET_ID}.embedding_model`,
(
SELECT
'Summarise the background, requirements and solution for this project' AS content
)
)
),
TOP_K => 10,
OPTIONS => '{{"fraction_lists_to_search": 0.01}}'
)
),
STRUCT(2048 AS max_output_tokens, TRUE AS flatten_json_output)
)),
engagement_deliverables as (
SELECT
{deal_id} AS deal_id,
NULL AS objectives_json,
NULL AS engagement_summary,
ml_generate_text_llm_result AS engagement_deliverables
FROM
ML.GENERATE_TEXT(
MODEL `{DATASET_ID}.gemini_flash`,
(
SELECT
CONCAT(
'What are the (up to 10) contractual deliverables listed for this project? Be concise, add no preamble and respond in JSON format using output fields "deliverable_number", "deliverable_details", "deliverable_format", "acceptance_criteria" using the following context:',
STRING_AGG(FORMAT("context: %s and reference: %s", base.content, base.uri), ',')) AS prompt
FROM VECTOR_SEARCH(
TABLE `{DATASET_ID}.{deal_id}_embeddings`,
'ml_generate_embedding_result',
(
SELECT
ml_generate_embedding_result,
content AS query
FROM
ML.GENERATE_EMBEDDING(
MODEL `{DATASET_ID}.embedding_model`,
(
SELECT
'What are the (up to 10) contractual deliverables listed for this project? Be concise and use the following context' AS content
)
)
),
TOP_K => 10,
OPTIONS => '{{"fraction_lists_to_search": 0.01}}'
)
),
STRUCT(2048 AS max_output_tokens, TRUE AS flatten_json_output)
))
SELECT
o.deal_id,
JSON_VALUE(REPLACE(REPLACE(s.engagement_summary,'```json',''),'```',''), "
.Requirements") AS requirements,
JSON_VALUE(REPLACE(REPLACE(s.engagement_summary,'```json',''),'```',''), "
.objective_number') AS objective_number,
JSON_EXTRACT_SCALAR(item, '
.expected_benefit') AS expected_benefit,
JSON_EXTRACT_SCALAR(item, '
.deliverable_number') AS deliverable_number,
JSON_EXTRACT_SCALAR(item, '
.deliverable_format') AS deliverable_format,
JSON_EXTRACT_SCALAR(item, '$.acceptance_criteria') AS acceptance_criteria
FROM UNNEST(JSON_EXTRACT_ARRAY(REPLACE(REPLACE(d.engagement_deliverables,'```json',''),'```',''))) AS item
) AS deliverables,
REPLACE(REPLACE(o.objectives_json,'```json',''),'```','') as objectives_json,
REPLACE(REPLACE(d.engagement_deliverables,'```json',''),'```','') as deliverables_json
FROM
objectives o
LEFT JOIN engagement_summary s ON o.deal_id = s.deal_id
LEFT JOIN engagement_deliverables d ON o.deal_id = d.deal_id)
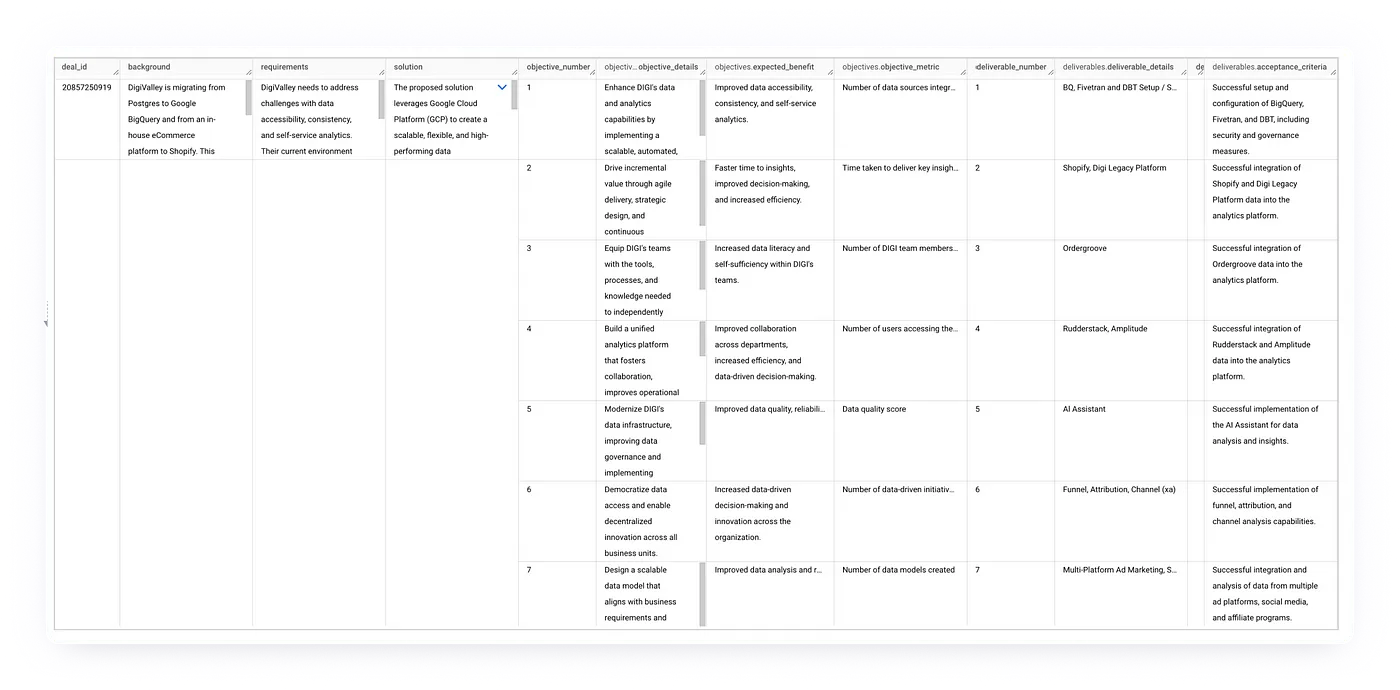
""")Looking now at the results of this processing pipeline you can see one row per engagement SoW PDF with the background, requirements, solution and then nested column sets for the objectives (including expected business benefit and measurement metric) and the contractual deliverables (with acceptance criteria).
In-total, including the pipelines to bring-in Slack messaging data and the various project KPI data sources such as Jira, Harvest and Hubspot, the complete processing pipeline for assessing the project engagement’s RAG status is shown in the diagram below.

Using ML.GENERATE_TEXT to Classify RAG Status
The final step in this process is to take all of the data gathered from the various project sources, concatenate the multi-row datasets they provide into JSON strings suitable for sending as part of an LLM prompt and then use them to create a series of prompts to the Gemini 1.5-FLASH LLM using BigQuery’s ML.GENERATE_TEXT function.
The full SQL query can be accessed as sample code here, but the key part of the command is where we concatenate all of these data sources into a prompt we send to the LLM, shown below:
FROM
ML.GENERATE_TEXT(
MODEL `analytics_ai.gemini_1_5_flash`,
(
SELECT
mc.company_name,
mc.deal_name,
mc.deal_description,
mc.project_name,
mc.engagement_month,
CONCAT(
'Provide a RAG status report for a Rittman Analytics client project in the following JSON format, where each field is filled with a brief, clear, and specific explanation of the project status in the context of the engagement background and requirements, the set of business objectives and contractual deliverables, the planned overall solution and the project documents published, meeting transcripts, slack messages and other project output and evidence. The possible statuses are RED, AMBER, or GREEN and the rationales should succinctly explain why each status was assigned (citing evidence), taking care to consider whether the engagement and project are for Discovery, Planning or Design and where the calculation of RAG status should relate to Rittman Analytics scope, financials, resourcing, schedule, technology OR the engagement is a project implementation where we are then responsible for the clients current technology, data quality, project scope, resourcing and schedule and for the project financials). In addition, provide a timeline of the significant (not all) activities (excluding daily standups and exchanges of pleasantries) and outputs of the engagement this month to accompany the RAG statuses. Use the format {\"overall_status\": \"<RED|AMBER|GREEN>\", \"overall_rationale\": \"<Brief explanation of the overall project status>\", \"scope_status\": \"<RED|AMBER|GREEN>\", \"scope_rationale\": \"<Brief explanation of the scope status>\", \"financials_status\": \"<RED|AMBER|GREEN>\", \"financials_rationale\": \"<Brief explanation of the financial status>\", \"schedule_status\": \"<RED|AMBER|GREEN>\", \"schedule_rationale\": \"<Brief explanation of the schedule status>\", \"data_quality_qa_status\": \"<RED|AMBER|GREEN>\", \"data_quality_qa_rationale\": \"<Brief explanation of the data quality & QA status>\", \"technology_status\": \"<RED|AMBER|GREEN>\", \"technology_rationale\": \"<Brief explanation of the technology status>\", \"resourcing_status\": \"<RED|AMBER|GREEN>\", \"resourcing_rationale\": \"<Brief explanation of the resourcing status>\", \"month_timeline\": \"<json_array_of_events_each_event_listing_event_date_and_event_description_sorted_in_date_order\"} Please use consistent, structured language for the rationales, ensuring they are concise (but specific, detailed) and actionable., for this company: ',
mc.company_name,
' for an engagement called "',COALESCE(mc.deal_name, ''),
'" with a description of "',COALESCE(mc.deal_description, ''),
'" with background to the engagement of "',COALESCE(mc.background, ''),
'" a set of client requirements given as "',COALESCE(mc.requirements, ''),
'" and business objectives defined by the client as "',COALESCE(mc.objectives_json, ''),
'", a solution proposed by Rittman Analytics to deliver "',COALESCE(mc.solution, ''),
'" with contractual deliverables due by engagement completion agreed as "',COALESCE(mc.deliverables_json, ''),
'" and a current sprint(s) called "',
COALESCE(mc.project_name, ''),
'" with these resulting project financial metrics : ',
COALESCE(p.all_project_financial_metrics, ''),
'" that worked on delivering these project tasks : ',
COALESCE(j.all_tasks, ''),
' published and posted these Confluence pages: ',
COALESCE(cp.all_docs_published, ''),
' generated these slack messaging posts: ',
COALESCE(s.all_messages, ''),
', and led to these meeting summaries ',
COALESCE(ms.meeting_summaries, ''),
' and these team-member feedback items from those meetings ',
COALESCE(t.meeting_comments, ''),
'. Remember to consider, if giving a RED or AMBER RAG status for a discovery engagement, whether the issues causing this red or amber status are affecting our ability to deliver the project or not.'
) AS prompt
FROM
...
),
STRUCT(
0.2 AS temperature,
4096 AS max_output_tokens,
TRUE AS flatten_json_output
)
)The output of this SQL, run within our warehouse dbt package every six hours and stored as a monthly snapshot of each project engagement’s performance, is then used as the main data source for our Project RAG Status dashboard delivered through Looker as shown below.

Note also the visualizations in the bottom-half of the dashboard page where we use the sentiment and engagement levels calculated elsewhere in this pipeline to gauge the “mood” of the project at this point-in-time, and the wordcloud visualization at the bottom right-hand side of the page that shows in a visual form the topics most prominent in the various stakeholder jobs-to-be-done’s, also extracted and assessed via LLM in this processing pipeline.
INTERESTED? FIND OUT MORE!
Rittman Analytics is a boutique data analytics consultancy that helps ambitious, digital-native businesses scale-up their approach to data, analytics and generative AI.
We’re authorised delivery partners for Google Cloud along with Oracle, Segment, Cube, Dagster, Preset, dbt Labs and Fivetran and are experts at helping you design an analytics solution that’s right for your organisation’s needs, use-cases and budget and working with you and your data team to successfully implement it.
If you’re looking for some help and assistance with your AI initiative or would just like to talk shop and share ideas and thoughts on what’s going on in your organisation and the wider data analytics world, contact us now to organise a 100%-free, no-obligation call — we’d love to hear from you!