Drill to Detail Ep.3 with Mike Percy on Apache Kudu
Episode 3 of the Drill to Detail podcast is now live on the podcast website and available for download on iTunes, and this week I’m very pleased to be joined by Cloudera’s Mike Percy, software engineer and lead evangelist within Cloudera for Apache Kudu, the new Cloudera-sponsored column-store data layer that takes the best features from HBase and Parquet and creates a storage layer specifically optimized for analytics.
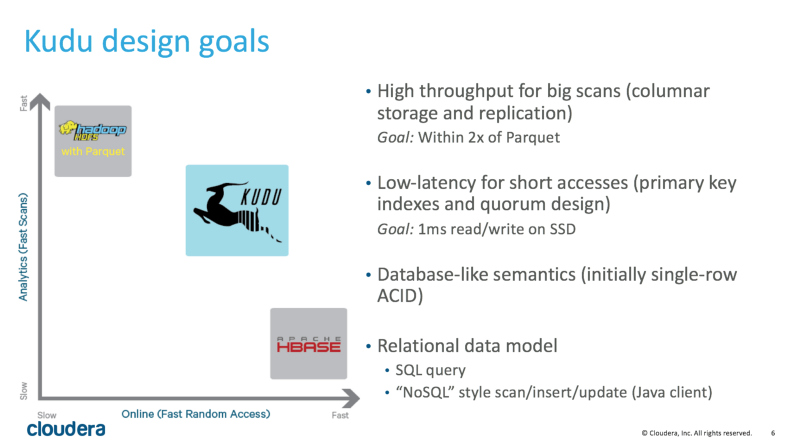
The problem that Kudu solves is something that becomes apparent to most Hadoop developers creating analytic applications that need to support BI-type query workloads against data arriving in real-time from streaming sources; whilst column-orientated file formats like Apache Parquet are great for supporting BI-style workloads they’re not that good for handling streaming data, and while HBase adds support for single-row inserts, updates and deletes to Hive, queries that require aggregation up from cell level don’t perform all that well, such that most projects I’ve worked on copy data from HBase into a format such as parquet before presenting that data out to users for query.
Apache Kudu, as Mike Percy explains in this video of one of his presentations on Kudu back in 2015, takes the “fast data” part of HBase and adds the “fast query” capability you get with column-store formats like parquet, and for Hadoop platforms that need to support this type of workload the aim is that it replaces HDFS as a more optimized form of storage for this type of workload and dataset.
[embed]https://www.youtube.com/watch?v=ifFg_o5bf6c[/embed]
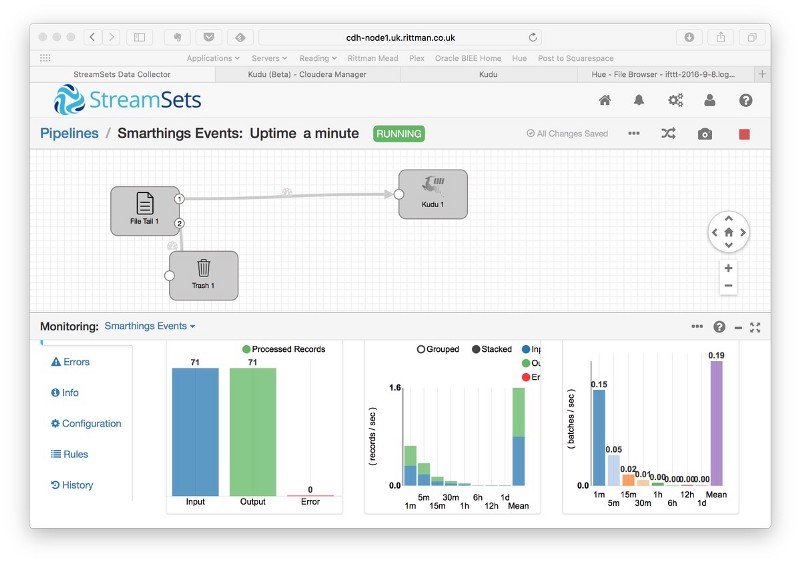
In-practice you tend to use Kudu as the storage format for Cloudera Impala queries, with Impala then gaining INSERT, UPDATE and DELETE capabilities, or you can do what I’ve been doing recently and use a tool such as StreamSets to load data into Kudu as just another destination type, as I’m doing in the screenshot below where home IoT sensor data lands in real-time into Kudu via Streamsets, and can be queried immediately using Impala SQL and a tool such as Hue or Oracle Data Visualization Desktop.
So thanks to Mike Percy and Cloudera for coming on this latest edition of the show, and you can read more about Kudu and the milestone 1.0 release on the Cloudera Vision blog.